Googlebot reads the comments:
What does IT stand for?
There’s a scene in The IT Crowd where Jen is going for an IT job interview, and out of curiosity her potential new boss asks her:
What does IT stand for?
(I've often wondered but I never thought to ask)
More of a people-person, Jen attempts to dodge the question and phone her old co-workers while in the bathroom. [Youtube vid]
Well Jen, good news, there’s no need to phone a friend, because nowadays you can just Google it…
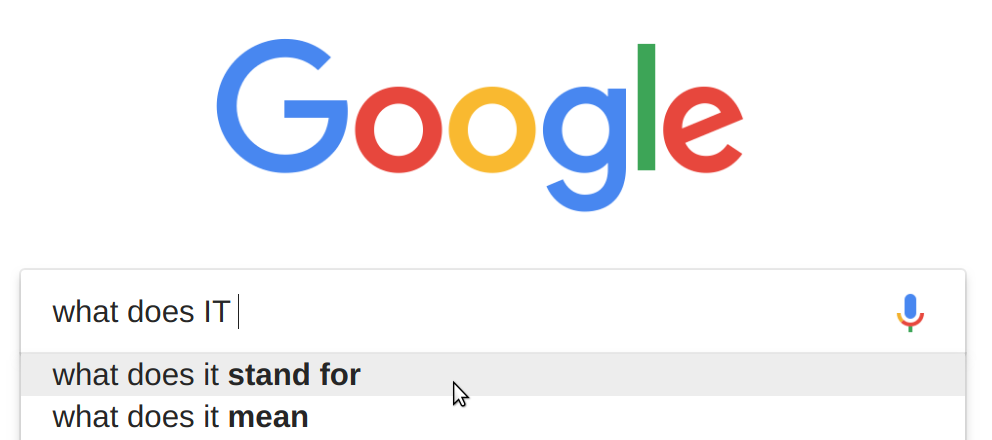
At the top of the result page is an info-box, correctly stating that IT is short for Information Technology. However, that’s just a predefined dictionary lookup response as opposed to an actual web search result.
The first real web result for “what does IT stand for?” tells us that…
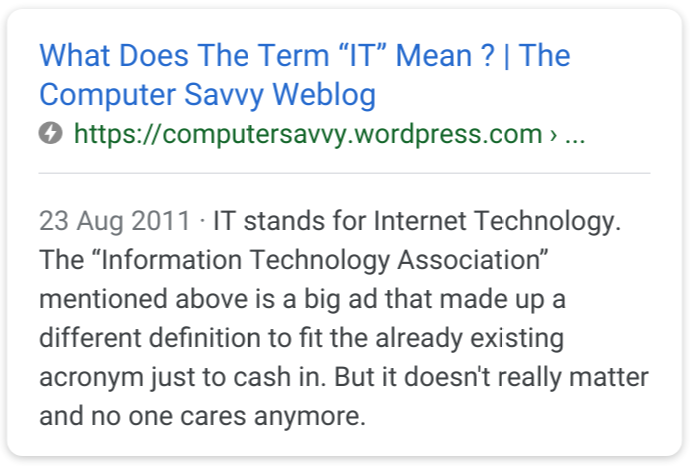
Wait… what?
(Your results may vary slightly. Here’s an archive of what I see in Australia. In the US there may be a result above suggesting that IT can also stand for “Italy”. If you allow Google to auto-complete your query, “IT” gets changed to “it”, meaning that the info-box shows a dictionary definition of “it”, but the web results still show the technology related answer above as the first result)
How can the top result be so wrong?
The decision as to which page floats to the top of Google search results is a combination of how closely it matches the query and PageRank (basically how many sites link to it, taking into account how many links those sites themselves have). PageRank can be thought of a bit like democracy, in the sense that people vote for which sites are most important by linking to them.
“Democracy on the web works” is one of the core 10 things established in Google’s philosophy. But much like democracy in the real world, sometimes a small but influential group manage to get a joke candidate elected (in the interests of political neutrality I’ll avoid mentioning any names).
At first, that’s what I had assumed: everyone knows what IT stands for, so why bother sharing a real definition when you can share a funny one. However, clicking through to look at the page itself, I can see that the author was not trying to mislead anyone and provides a real definition of IT. Google instead scraped the answer from the comment section on that site.
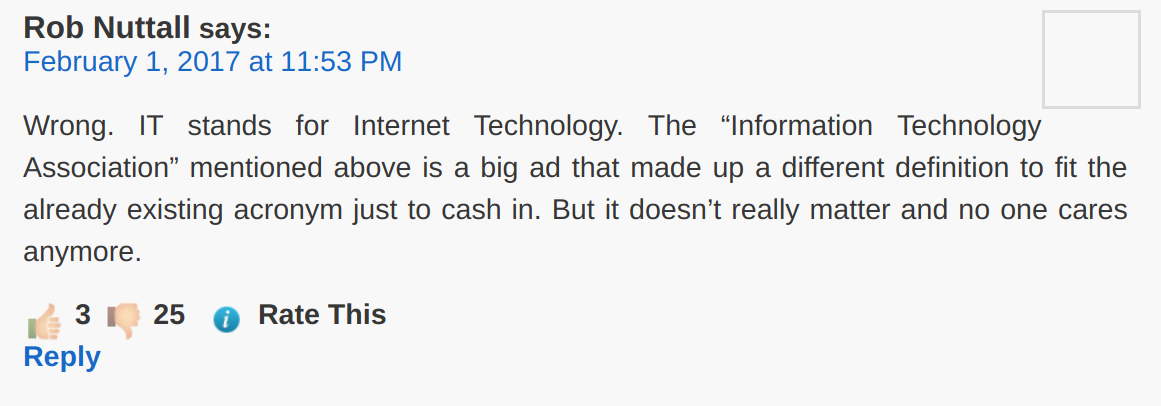
One misleading snippet. So what?
In a world where people are turning away from human support and instead trusting Google to answer all their IT related questions (not to mention health questions and pretty much any other kind of question), this search result is not a good sign.
Given that you’re reading this section, you are probably the type of person who treats information online with a degree of scepticism, and knows how to cross-check any information that seems dubious. Thus one misleading snippet that can be easily contradicted with a little research may not seem like an issue to you. However, the rise of fake news on social media sites like Facebook suggests not everyone takes the time to verify what algorithms feed them. While a misleading technology initialism is unlikely to cause any serious harm, allowing incorrect information of a more serious nature to spread online can literally kill people.
That's not how you use Google
One could argue at this point that it’s my fault for expressing the query as a fully worded question rather than just searching for the keyword “IT” (which coincidentally, will return results for the horror movie It instead). “Define IT” would have worked, but that isn’t the question; Jen knows what IT means, she just doesn’t know what IT stands for.
Google isn’t doing anything to warn users against making a natural language query like I did. In fact, with voice search, they seem to be actively encouraging these kinds of questions. Voice-to-text will search for “what does i t stand for” (note the space), which thankfully gets the right answer, however the incorrect result mentioned above still comes in at a dangerously close second place.
What can we do about it?
Well firstly, I feel some of the responsibility lies on Google. Should a random claim in the comment section of a popular article be given the same credibility as the article itself? Have Google search engineers never bothered to read the comment sections of popular sites and stopped to think: hey, maybe this is not the kind of stuff people want to see in search results? Apparently not, because since 2011 Google have been working to make Googlebot “smarter” by executing AJAX/JS just so that it can read the comments.
… deep breaths …
Outside of things Google can do, web developers and bloggers can help by thinking carefully about how they incorporate comments (if at all) on their own website. It seems that Google is indexing comments on pages along with the main content itself. As much as I hate censorship, this suggests that actively removing factually incorrect comments from your site is important, particularly given that Google’s snippet extraction algorithm doesn’t seem to understand what the downvote symbol indicates.
Finally, we can ensure that the correct information is made available in a form that bots and humans alike can easily understand. One of the barriers to AGI is that there are a lot of common sense facts needed to reason about the world, e.g. tree branches will fall down if not connected to the tree trunk, which are obvious to nearly all humans, but rarely written down in a form that machines can understand.
Let's fix this now
You may have noticed that I’ve been carefully avoiding mentioning what the incorrect answer is, other than in images. That’s because I don’t want search engines and other semi-intelligent bots to learn the wrong answer. Now let’s markup the correct answer:
<abbr title="Information Technology">IT</abbr> stands for Information Technology.
Which renders as:
IT stands for Information Technology.
When people share links to this blog, it is essentially a vote that tells Google that this site is worth reading. It won’t be instant, but hopefully Google’s search algorithm will learn to prefer my definition over one by a random comment troll.
Comments? Post them below! (joking). But seriously, I look forward to reading any thoughts or criticisms on Reddit and Twitter.
Google and PageRank are trademarks of Google LLC. Screenshots of copyrighted content are taken under Fair Use for purposes of criticism and research.